 |
 |
|
| このサイトは、もともと作者の自分用メモとして書き始めたものです。書いてあることが全て正しいとは限りません。他の文献、オフィシャルなサイトも確認して、自己責任にて利用してください。 | ||
|
|
|
| このサイトは、もともと作者の自分用メモとして書き始めたものです。書いてあることが全て正しいとは限りません。他の文献、オフィシャルなサイトも確認して、自己責任にて利用してください。 | ||
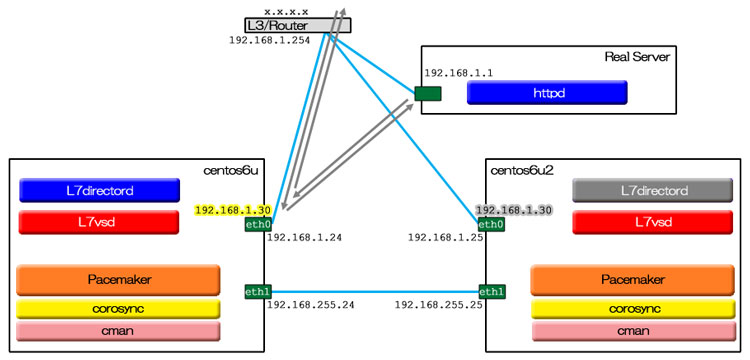
前に Ultra Monkeyの元祖 L4版 について書いた。ここでは、OSI参照モデルで言うところの第7層、つまりアプリケーション層でのロードバランスを行う UltraMonkey-L7 を、RHEL/CentOS 6.4 上で HA(高可用性)構成で実装する方法を解説する。UltraMokey-L7のSourceForgeサイトの文書 では、L4 の時の流れを引き継いで heartbeat と組み合わせるやり方が中心に語られている。しかし、RHEL/CentOS では、heartbeat が標準パッケージになく、逆に Pacemaker が RHEL/CentOS 6.4 で標準パッケージになったので、当ページでは Pacemaker との組み合わせを用いる。この検証は、CentOS 6上のKVM仮想マシンで行なった。
Pacemeker 使用時のインストールマニュアルも UltraMonkey-L7のサイト に一応はあるのだが、中途半端に heartbeat の影を引きずっていて、内容もやや不十分。使用パッケージも Linux-HA JAPAN が独自に選定したもので、Pacemaker のバージョンがやや古い(※下記のコラム参照)。当ページでは、それも参考にさせていただきつつ、なるべく標準パッケージを使って、UltraMonkey-L7 + Pacemaker + corosync というコンビネーションで組み上げる手順を示す。
なお、Linux-HA JAPAN 提供 Pacemakerパッケージを使った検証も行い、それは次ページにまとめた。
まず、クラスタの基盤となる CMAN 及び corosync と、クラスタリソースを実際に制御する Pacemaker をインストール。
# yum install pacemaker corosync cman
Installing:
cman x86_64 3.0.12.1-49.el6_4.2 updates 443 k
corosync x86_64 1.4.1-15.el6_4.1 updates 202 k
pacemaker x86_64 1.1.8-7.el6 base 400 k
Installing for dependencies:
cluster-glue x86_64 1.0.5-6.el6 base 116 k
cluster-glue-libs x86_64 1.0.5-6.el6 base 116 k
clusterlib x86_64 3.0.12.1-49.el6_4.2 updates 101 k
corosynclib x86_64 1.4.1-15.el6_4.1 updates 183 k
fence-virt x86_64 0.2.3-13.el6 base 37 k
modcluster x86_64 0.16.2-20.el6 base 191 k
openais x86_64 1.1.1-7.el6 base 192 k
openaislib x86_64 1.1.1-7.el6 base 82 k
ricci x86_64 0.16.2-63.el6 base 626 k
libqb x86_64 0.14.2-3.el6 base 66 k
pacemaker-cli x86_64 1.1.8-7.el6 base 173 k
pacemaker-cluster-libs x86_64 1.1.8-7.el6 base 67 k
pacemaker-libs x86_64 1.1.8-7.el6 base 383 k
perl-TimeDate noarch 1:1.16-11.1.el6 base 34 k
resource-agents x86_64 3.9.2-21.el6_4.3 updates 481 k
クラスタの設定やコントロールを行うコマンドラインツール pcs をインストール(※)。
# yum install pcs
Installing:
pcs noarch 0.9.26-10.el6_4.1 updates 72 k
主に CMAN の設定ファイルをメンテナンスするツール ccs をインストール。
# yum install ccs
Installing:
ccs x86_64 0.16.2-63.el6 base 48 k
※ Pacemaker 1.1.7 までは pcs と同種のツールである crm (crmsh) が含まれていたのだが、1.1.8 から急に含まれなくなった(joshua.hoblitt)。現在は、ひとつのプロジェクトとして独立したようだ。これからは pcs が主流になりそうなので、当ページでは pcs をメインに使うことにする。ただ、正直を言うと、今の pcs はまだ機能が一部欠けていてドキュメントも不足しており、先達の crm のほうが使い勝手がいい。crm をインストールするには、OpenSUSE のサイトから repo 定義ファイルをダウンロードして yum で crmsh パッケージをインストールすればいい。入れておいて害も損もないし、実際、当解説の中にも crm でしか投入できない設定がある。
自分の環境では、下記の依存パッケージが欠けていたので先にインストールしておいた。
# yum install perl-Time-HiRes
SourceForgeのUltraMonkey-L7ダウンロードページから ultramonkeyl7-repo-3.1.0-1.el6.x86_64.rpm をダウンロード。これは、単なる yum のrepo定義ファイルでなく、実際のパッケージ一式も含んだちょっと変わったrepoパッケージだ。ダウンロードしたrepoパッケージをインストール。
# rpm -ivh ultramonkeyl7-repo-3.1.0-1.el6.x86_64.rpm
インストールすると、/etc/yum.repos.d/ にrepo定義ファイル、/opt/ultramonkey-l7/ultramonkeyl7/ 配下に rpmパッケージ群が展開される。これで ultramonkey-L7 がインストールできる。
# yum install ultramonkeyl7
Installing:
ultramonkeyl7 x86_64 3.1.0-1.el6 ultramonkeyl7 1.6 M
repo一式はもう必要なくなったので捨てる。
# rpm -e ultramonkeyl7-repo
l7vsd と l7directord を起動するためのリソースエージェントをインストール。
# cp -p /usr/share/doc/ultramonkeyl7-3.1.0/heartbeat-ra/{L7vsd,L7directord} \
/usr/lib/ocf/resource.d/heartbeat
Linux-HA JAPAN の提供する pacemaker-repo パッケージの中に、必要なリソースエージェントスクリプトがひとつあるので、Linux-HA Japan提供パッケージ一覧 から Pacemakerリポジトリパッケージ (RHEL6) へと進み、pacemaker-1.0.13-1.1.el6.x86_64.repo.tar.gz をダウンロードし、/tmp/ に展開。
# cd /tmp # tar xzvf /PATH/TO/pacemaker-1.0.13-1.1.el6.x86_64.repo.tar.gz
/tmp/pacemaker-1.0.13-1.1.el6.x86_64.repo/rpm/ に展開された pm_extras-1.3-1.el6.x86_64.rpm から、VIPcheck だけをインストール。
# cd / # rpm2cpio \ /tmp/pacemaker-1.0.13-1.1.el6.x86_64.repo/rpm/pm_extras-1.3-1.el6.x86_64.rpm | cpio -imv */heartbeat/VIPcheck
コマンドでやるのが面倒くさければ、rpm ファイルを file-roller で開き、./usr/lib/ocf/resource.d/heartbeat/VIPcheck をどこかへ一時的に取り出してから、/usr/lib/ocf/resource.d/heartbeat/ へコピーし root:root 755 に chmod しても結果は同じだ。
クラスタ内でノードを短い名前で扱えるよう、hostsファイルなどを調整しておいたほうがよい。
HOSTNAME=centos6u.hoge.local
のようになっていたら、ドメイン部を取り除いて、
HOSTNAME=centos6u
のように直す。
domain hoge.local
がなければ加える。
RedHat/CentOS 6 のOSインストール直後の状態では、IPv4 と IPv6 のループバックアドレスしか書かれていない。自ホストはもちろんだが、クラスタファームを構成するノードはリストしておいたほうがいい(実際は自分以外は書かなくても動く)。
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.24 centos6u.hoge.local centos6u 192.168.1.25 centos6u2.hoge.local centos6u2
反映のため、マシンを一旦リブート。
UltraMonkey-L7 単独の動作試験から始めたいところだが、フローティングIP が存在しないことには L7vsd が立ち上げられない。そのため、先に CMAN + Pacemaker の基本設定をしておく。corosync の設定ファイルは /etc/corosync/corosync.conf だが、当ページの組み合わせでは、corosync は CMAN 経由で起動され、corosync.conf はスルーされる。代わりに、CMAN の設定ファイルである /etc/cluster/cluster.conf を整備する。
まず、クォーラムが成立しない状態でも CMAN が起動できるよう、CMAN の起動オプション設定ファイル /etc/sysconfig/cman を調整。
#CMAN_QUORUM_TIMEOUT=45 <--変更前 CMAN_QUORUM_TIMEOUT=0 <--変更後
cluster.conf をノード間で同期してくれるサービス ricci を起動。
# service ricci start
cluster.conf のベースを作る。monkeyclst1 とした部分は適当なクラスタファームの名称。
# ccs_tool create monkeyclst1
`man cluster.conf` を読み /etc/cluster/cluster.conf を編集。インデントは後で ccs ツールで同期やアクティベートを行うと勝手に調整されるので几帳面に揃えても無駄。
<?xml version="1.0"?>
<cluster config_version="12" name="monkeyclst1">
<logging debug="off" syslog_facility="local5" syslog_priority="info" to_logfile="no" to_syslog="yes"/>
<cman expected_votes="1" two_node="1"/> <--ノード台数3台未満の場合は記述
<clusternodes>
<clusternode name="centos6u" nodeid="24"> <--ノードホストの定義とともにハートビートLANの定義となる
<altname name="192.168.255.24"/> <--第2ハートビートLANの定義
</clusternode>
<clusternode name="centos6u2" nodeid="25"> <--同様にノード2について記述
<altname name="192.168.255.25"/>
</clusternode>
</clusternodes>
<fencedevices/>
<rm>
<failoverdomains/>
<resources/>
</rm>
</cluster>
上記でログを syslog 経由にしたので、/etc/rsyslog.conf に下記定義を追加。
local5.* /var/log/cluster/cluster.log
文法チェックを実行する。
# ccs_config_validate cluster.conf
最初だけは、まだノードファームが形成されていないので、cluster.conf を他ノードへ sftp や scp などで手動コピー。他ノードでも ricci デーモンを起動したら、チェックと同期を実行する。
# ccs -h centos6u --checkconf # ccs -h centos6u --sync --activate
ファームが形成されてノードが認識されていることを確認。
# ccs -h centos6u --lsnodes
または
# cman_tool nodes
CMAN と Pacemaker を立ち上げ、状態を確認。実際のところ、pacemaker の initスクリプトは、事前に CMAN を立ち上げる処理を含んでいるので、いきなり pacemaker を立ち上げても機能する。
# service cman start # service pacemaker start # pcs status
マスターノード上で設定の続きを。
STONITH の実装は本来必須だが、後で追加設定するまでは無効にしておく。また、今回のクラスタは2台構成なので、Pacemaker側でもクォーラム喪失は無視するよう設定しておく。
# pcs property set stonith-enabled=false # pcs property set no-quorum-policy=ignore # pcs property Cluster Properties: dc-version: 1.1.8-7.el6-394e906 cluster-infrastructure: classic openais (with plugin) expected-quorum-votes: 2 stonith-enabled: false no-quorum-policy: ignore
起動状態を確認。
# corosync-cfgtool -s
Printing ring status.
Local node ID 24
RING ID 0
id = 192.168.255.24
status = ring 0 active with no faults
RING ID 1
id = 192.168.1.24
status = ring 1 active with no faults
さて、IPaddr2 というリソースエージェントを使ってフローティングIPリソースを作ろう。実際やってみると、残念ながらこのバージョンの pcs ではリソース定義新規作成と同時に複数のオペレーションを定義することができなかった。リソースを作ってからオペレーションを追加していくというやり方でやりすごす。
# pcs resource create FIP1 ocf:heartbeat:IPaddr2 \ ip=192.168.1.30 nic=eth0 cidr_netmask=24 # pcs resource add_operation FIP1 \ start interval=0s timeout=60s on-fail=restart # pcs resource add_operation FIP1 \ monitor interval=30s timeout=60s on-fail=restart # pcs resource add_operation FIP1 \ stop interval=0s timeout=60s on-fail=block
リソースエージェント(RA)とは、実際にサービスやリソース(例えばフローティングIP)を立ち上げたり、リソースの死活監視(ゲイトウェイへ定期的にpingを飛ばすことによるインターフェイス死活監視など) をするためのプログラムで、/usr/lib/ocf/resource.d/ 配下にディレクトリ階層で管理されている。例えば、上記で指定している ocf:heartbeat:IPaddr2 は、resource.d/heartbeat/ にある IPaddr2 というファイル名のシェルスクリプトだ。中間フィールドの heartbeat をリソースプロバイダ と呼ぶ。各スクリプトは Open Clustering Framework Resource Agent API という規格に沿って書かれている。OCF についてもっと深く知りたい、あるいは自分でカスタムエージェントを書きたいという人は The OCF Resource Agent Developer’s Guide を読むといいだろう。
どんなプロバイダや RA があるかやその使い方は、pcs の場合、以下のようなコマンドで調べることができる。
RA規格(例えばocf)をリストアップするには:
# pcs resource standards
プロバイダをリストアップするには:
# pcs resource providers
リソースエージェントをリストアップするには:
# pcs resource agents ocf:heartbeat
リソースエージェントの説明を表示するには:
# pcs resource describe ocf:heartbeat:IPaddr2
または
# crm ra info ocf:heartbeat:IPaddr2
きちんと定義されたかどうか確認する。
# pcs status <--出来上がった途端にもうフローティングIPはstartedになっているはずだ # pcs resource show # pcs resource show FIP1 # ip addr show <--フローティングIPが確かに発生していることを確認 # pcs cluster cib
最後のコマンドは、cib のXMLを表示する。cib とは Cluster Information Base の略で、クラスタに関しての、定義やオプション、ノード、リソース、それらの関係性、ステータスなどを管理するデータベース。実体は /var/lib/pacemaker/cib/ にある(Pacemaker 1.0 では /var/lib/heartbeat/crm/)。pcs や crm などのツールが登場するまでは(その時代を筆者は知らないが)、その複雑なXMLファイルを直接編集しなければならなかったらしい。cib は corosync によって、クラスタファームを構成するノード間で同期される。corosync のログを見ていると、どうやら一種の diff を採って差分転送しているようだ。
何はともあれ、UltraMonkey-L7 - SourceForge.JP -> 文書 にある UltraMonkey-L7 Pacemaker 環境インストールマニュアル を読むべし。
l7directord の設定ファイルサンプルをコピーして土台を作る。
# cp -p /etc/ha.d/conf/l7directord.cf{.sample,}
l7directord.conf を然るべく編集。
振り分け先の実サーバ上で実サービス(httpd) を立ち上げておいてから、ロードバランサの基本的な動作テスト。
# service l7vsd start # service l7directord start # l7vsadm -l -n
想定通り動くようであれば、クラスタの作り込みのために一旦 UltraMonkey-L7 を落とす。
# service l7directord stop # service l7vsd stop
ローカルディスクチェック用のリソースは、制約 (constraint) と密接に関係しているので後述する。
# pcs resource create L7VSD ocf:heartbeat:L7vsd # pcs resource add_operation L7VSD \ start interval=0s timeout=60s on-fail=restart # pcs resource add_operation L7VSD \ monitor interval=30s timeout=60s on-fail=restart # pcs resource add_operation L7VSD \ stop interval=0s timeout=60s on-fail=block # pcs resource show L7VSD
# pcs resource create L7DRCTOR1 ocf:heartbeat:L7directord # pcs resource add_operation L7DRCTOR1 \ start interval=0s timeout=60s on-fail=restart start-delay=5s # pcs resource add_operation L7DRCTOR1 \ monitor interval=30s timeout=60s on-fail=restart # pcs resource add_operation L7DRCTOR1 \ stop interval=0s timeout=60s on-fail=block # pcs resource show L7DRCTOR1
# pcs resource create PINGD ocf:pacemaker:ping \ name=pingd_score \ host_list="192.168.1.254 192.168.1.253" multiplier=100 # pcs resource add_operation PINGD \ start interval=0s timeout=60s on-fail=restart # pcs resource add_operation PINGD \ monitor interval=10s timeout=30s on-fail=restart # pcs resource add_operation PINGD \ stop interval=0s timeout=60s on-fail=ignore # pcs resource show PINGD
UltraMonkey-L7 のドキュメントでは ocf:pacemaker:ping でなく pingd を使う記述になってるが、このバージョンの Pacemaker に付属している pingd の中身を読んでみると「pingdはもう古い。より確実なテストのできるpingを使え」とあるので、それに従った。LANケーブルの抜線によるフェイルオーバー試験でも、pingd ではどうしてもフェイルオーバーがトリガーされてくれず、ping に差し替えるとうまくいった。
pacemaker:ping リソースエージェントは、fping バイナリがシステムにインストールされていると、ping コマンドでなく fping コマンドを使うようにできている。筆者の検証では、host_list に複数のターゲットを指定した場合に、ping コマンド動作ではうまく動かなかった。fping のRPMパッケージは RepoForge からダウンロードできる。
Linux-HA JAPANの提供するこのリソースエージェントは、上記の pingd のように特定のIPアドレスに対して ping 確認をするのだが、フローティングIPが存在していないことを確認するためのものなので、ping が飛ぶと false、飛ばないと true を返す。なので、定義した途端活性化してエラーになるが、びっくりしてはいけない。もう言うまでもなく、target_ip に指定するのは先に作った FIP1 のIPアドレスだ。
# pcs resource create VIPCHK1 ocf:heartbeat:VIPcheck \ target_ip=192.168.1.30 count=1 wait=10 # pcs resource add_operation VIPCHK1 \ start interval=0s timeout=90s on-fail=restart start-delay=4s # pcs resource show VIPCHK1
リソースエージェントの単体テストの手段が用意されている。ocf-tester というコマンドだ。例えば、
# ocf-tester -v -n VIPCHK1 \
-o target_ip=192.168.1.30 -o count=1 -o wait=10 \
/usr/lib/ocf/resource.d/heartbeat/VIPcheck
とやると、VIPcheck の動作がテストできる。なお、VIPcheck の場合、先ほど言ったように、フローティングIPを停止しておかないと 1 (false) が返ってきてしまうので、テストの前に `pcs resource stop FIP1' で FIPリソースを停止しておくのを忘れずに。
ocf-testerを介してリソースエージェントを走らせるとデバグオプションが有効になるようなのだが、pacemaker:ping の場合、デバグ出力ルーティンが不足しているため、せっかく ocf-tester に掛けても何が行われているのか分かりにくい。差分を採っておいたので当てていただくといいだろう。
リソース制約 (Constraints) とは、クラスタリソース間の依存関係や、どのノード上で優先的に活性化させるかなどといった規定のことだ。先に定義した FIP衝突チェックリソースや、ネットワーク経路死活確認リソースも、ちゃんと役に立つかどうかはリソース制約にかかっている。
まず、ノード間を一団となって移動できるよう、ロードバランサの最前線リソースをグループにまとめる。
# pcs resource group add GrpBalancer VIPCHK1 FIP1 L7DRCTOR1
全てのノードで同時に活性化させる必要のあるリソースを、クローンにしておく。
# pcs resource clone PINGD # pcs resource show PINGD-clone # pcs resource clone L7VSD # pcs resource show L7VSD-clone # pcs status
ひとつのノード上で一緒に活性化すべきリソースを定義。「GrpBalancer は必ず、PINGD-clone の活性化しているノード上で活性化すべき」等々。
# pcs constraint colocation add GrpBalancer PINGD-clone INFINITY \ id=col-GrpBalancer-with-PINGD # pcs constraint colocation add GrpBalancer L7VSD-clone INFINITY \ id=col-GrpBalancer-with L7VSD
結果、cib 上には下記のようなパラメータとして登録される。
<rsc_colocation id="col-GrpBalancer-with-PINGD" rsc="GrpBalancer" score="INFINITY" with-rsc="PINGD-clone"/> <rsc_colocation id="col-GrpBalancer-with-L7VSD" rsc="GrpBalancer" score="INFINITY" with-rsc="L7VSD-clone"/>
1行目で言うと、クラスタはまず、PINGD-clone をどのノード上で活性化するかを決める。そして、GrpBalancer をその同じノード上で活性化する。そのノードでもしも PINGD-clone が活性化できなければ GrpBalancer も活性化されない。ただし、GrpBalancer が活性化できなかったとしても PINGD-clone を敢えて停止したりはしない。
活性順を定義。例えば L7VSD は GrpBalancer より先に活性化されなければならない。symmetrical 属性は、true だと停止する際の順序が開始時とは逆になる。
# pcs constraint order add \ PINGD-clone GrpBalancer score=INFINITY symmetrical=false \ id=order-PINGD-then-GrpBalancer # pcs constraint order add \ L7VSD-clone GrpBalancer score=INFINITY symmetrical=true \ id=order-L7VSD-then-GrpBalancer # pcs constraint order add \ VIPCHK1 FIP1 score=INFINITY symmetrical=true \ id=order-VIPCHK1-then-FIP1 # pcs constraint order add \ FIP1 L7DRCTOR1 score=INFINITY symmetrical=true \ id=order-FIP1-then-L7DRCTOR1 # pcs constraint show all
3~4行目による cib エントリを以下に示す。
<rsc_order first="VIPCHK1" id="order-VIPCHK1-then-FIP1" score="INFINITY" symmetrical="true" then="FIP1"/> <rsc_order first="FIP1" id="order-FIP1-then-L7DRCTOR1" score="INFINITY" symmetrical="true" then="L7DRCTOR1"/>
この2エントリによって3つのリソースの依存関係を定義している。order constraint の1エントリは2つのリソースの関係性しか定義できないので、このように分けて設定する。活性化の際には VIPCHK1 を FIP1 より先に活性化し、非活性化の際には逆に FIP1 -> VIPCHK1 の順で停止される。VIPCHK1 を活性化しようとした時に既に FIP1 が活性だった場合には、FIP1 を停止し再活性化してから VIPCHK1 が活性化される。VIPCHK1 が活性化できない場合には FIP1 も活性化されない。2つのエントリの複合によって、開始時: VIPCHK1 -> FIP1 -> L7DRCTOR1、停止時: L7DRCTOR1 -> FIP1 -> VIPCHK1 という依存関係が構成される。
ここまで、ほとんど制約エントリ毎ばらばらに、しかも all or nothing でしか効果を解説してこなかったが、実際には、順序制約やコロケーション制約などそれぞれの重み(score) と、リソース毎のプライオリティ (リソースのmeta要素のpriority属性) が総合計算されて最終的な動作が決定するようだ。Cluster Labs の Ordering Explained や Colocation Explained という文書が理解の助けになるが、筆者のようなエセ理系脳ではまだ理解しきれない。
最後の難関が、cib内の変数と演算子を使った制約ルールというやつだ。実は、このバージョンの pcs では投入することができない(困ったものだ)。crm を使えば入れられる(あとで軽く紹介する)のだが、せっかく検証したので、cibadmin というコマンドを使うやり方を紹介しておこう。cibadmin コマンドは corosync などと一緒にインストールされる。じゃあ最初から crm でやればいい、と言われればその通り。
まず、cib から、<constraints> ブロックの内容だけをファイルに書き出す。ファイル名は任意。
# cibadmin --query --scope constraints >constraints.xml
その constraints.xml をテキストエディタで開き、末尾の </constraints> のすぐ上に、以下のコード挿入して保存する。行頭のインデントの数は、cib 本体にマージすると勝手に調整されるので気にしても仕方がない。
<rsc_location id="loc-GrpBalancer" rsc="GrpBalancer">
<rule id="loc-GrpBalancer-with-primary" score="200">
<expression attribute="#uname" operation="eq" value="centos6u" id="loc-GrpBalancer-primary-exp"/>
</rule>
<rule id="loc-GrpBalancer-slave" score="100">
<expression attribute="#uname" operation="eq" value="centos6u2" id="loc-GrpBalancer-slave-exp"/>
</rule>
<rule id="loc-GrpBalancer-ping-ng" score="-INFINITY" boolean-op="or">
<expression operation="not_defined" attribute="pingd_score" id="loc-GrpBalancer-ping_set-nodef"/>
<expression attribute="pingd_score" operation="lt" value="200" id="loc-GrpBalancer-ping-count"/>
</rule>
</rsc_location>
意味はこうだ:
GrpBalancer リソース(グループ)は、なるべくノード名=centos6u 上で起動させたい(スコアが高い)。
ノード名=centos6u2 上では、他の条件が合えば起動させてもよい(スコアが低い)。
cibのステータスに pingd_score 属性が存在しない(つまりocf:pacemaker:pingが活性化していない)か、
あるいは、pingd_score < 200 の時には、GrpBalancer リソースは活性化してはならない(スコアがマイナス無限大)。
ここでは pingd_score に要求する値を 200 にしている。これは、PINGDリソースの設定が、pingターゲット2ヶ所 x multiplier=100 だから。1ヶ所にしか飛ばさないように設定した場合は、100 にしないと常に false になってしまうので注意。
cib 本体の <contraints> ブロックをこの xml の内容で差し替える。
# cibadmin --replace --scope constraints -x constraints.xml
または、標準入力から読み取る -p オプションを利用して、
# cat constraints.xml |cibadmin --replace --scope constraints -p
投入できたか確認。
# pcs constraint show all # pcs status
同じことを crm でやると、これだけ済む。
# crm configure crm# location loc-GrpBalancer GrpBalancer \ rule $id=loc-GrpBalancer-primary 200: #uname eq centos6u \ rule $id=loc-GrpBalancer-slave 100: #uname eq centos6u2 \ rule $id=loc-GrpBalancer-ping-ng -inf: \ not_defined pingd_score or pingd_score lt 200 crm# commit
さあ、一通り設定が終わったので、クラスタをきれいに立ち上げなおす。
# service pacemaker stop # service cman restart # service pacemaker start # pcs status # l7vsadm -l -n
自動起動するよう設定。
# chkconfig cman on # chkconfig pacemaker on # chkconfig ricci on
RHEL/CentOS 6 のパッケージで組む当実装では、次ページのやり方で使う heartbeat:diskd リソースエージェントが存在しない(追加インストールしようとしたがクラスタライブラリのバージョンが合わないらしくインストールできない)。diskd だとマウントせずに RAW読み取りチェックができるのが魅力なのだが、こちらでは代替手段として、マウントして読み取りまたは書き込み試験を行う RA を使う。heartbeat:Filesystem と、RedHat系パッケージ特有と思われる redhat:fs.sh から好きな方を選べばよい (いずれも resource-agents パッケージのコンポーネント)。ふたつとも機能はほとんど同じだが、Filesystem のほうは、ローカルディスクの場合はクローンすると動かないのに対して、fs.sh は ping などと同様にクローンとして動かすことができる。
ここでまたもや、一部パラメータが現在の pcs コマンドでは投入できないことが判明したので、定義は crm で投入する。
これらのチェックリソースはどうしてもファイルシステムをマウントするところから始めたがるので、死活監視用パーティションとマウントポイントを用意しておかなければならない。今回の検証環境ではクラスタメンバは仮想マシンなので、各々のノードに死活チェック専用の小さなディスクボリューム(10MB) を追加で与えるやり方とした。
マシンに KVM でディスクボリュームを追加したら、パーティションを作ってフォーマット。
# parted /dev/vdb (parted) mklabel msdos (parted) mkpart primary ext2 0% 100% (parted) print Number Start End Size Type File system Flags 1 512B 12.6MB 12.6MB primary (parted) quit # mkfs.ext3 -m 0 -L alivedisk /dev/vdb1 # tune2fs -c 0 -i 0 -O ^dir_index -j /dev/vdb1 # mkdir /mnt/alivedisk
チェック深度には、存在確認のみ (depth:0 デフォルト)、読み取りテスト (depth:10)、書き込みと読み取り (depth:20) があり、それを指定するには、リソーステスト系RA共通の指定方法である OCF_CHECK_LEVEL 属性を使用する(<-これが今のpcsでは正しく投入できない)。ディスク異常は緊急事態なので、monitor オペレーションと stop (つまりアンマウント)オペレーションが失敗した場合にはノードをフェンシングする fence を指定した。
# crm configure crm# primitive RHFS ocf:redhat:fs.sh \ params name=alivedisk device=/dev/vdb1 mountpoint=/mnt/alivedisk fstype=ext3 \ op start interval=0s timeout=60s start-delay=5s on-fail=restart \ op monitor interval=10s timeout=30s on-fail=fence OCF_CHECK_LEVEL=10 \ op stop interval=0s timeout=60s on-fail=fence
crm# clone RHFS-clone RHFS
crm# colocation col-GrpBalancer-with-RHFS inf: GrpBalancer RHFS-clone crm# order order-RHFS-then-GrpBalancer mandatory: \ RHFS-clone GrpBalancer symmetrical=false crm# commit
Filesystem RA は、ローカルディスクを対象とする場合、クローンだと動作を拒否することが分かった (`not configured'エラーが出て start しない)。そのため、各ノード毎に個別のリソースを作ってやらなければならず、少々定義が増える。
# crm configure crm# primitive HBFS-primary ocf:heartbeat:Filesystem \ params device=/dev/vdb1 directory=/mnt/alivedisk fstype=ext3 run_fsck=no \ op start interval=0s timeout=60s on-fail=restart start-delay=5s \ op monitor interval=10s timeout=30s on-fail=fence OCF_CHECK_LEVEL=10 \ op stop interval=0s timeout=60s on-fail=fence crm# primitive HBFS-slave ocf:heartbeat:Filesystem \ params device=/dev/vdb1 directory=/mnt/alivedisk fstype=ext3 run_fsck=no \ op start interval=0s timeout=60s on-fail=restart start-delay=5s \ op monitor interval=10s timeout=30s on-fail=fence OCF_CHECK_LEVEL=10 \ op stop interval=0s timeout=60s on-fail=fence
crm# location loc-HBFS-primary inf: HBFS-primary centos6u crm# location loc-HBFS-slave inf: HBFS-primary centos6u2 crm# colocation col-GrpBalancer-with-HBFS-primary inf: \ GrpBalancer HBFS-primary crm# colocation col-GrpBalancer-with-HBFS-slave inf: \ GrpBalancer HBFS-slave crm# order order-HBFS-primary-then-GrpBalancer mandatory: \ HBFS-primary GrpBalancer symmetrical=false crm# order order-HBFS-slave-then-GrpBalancer mandatory: \ HBFS-slave GrpBalancer symmetrical=false crm# commit
実験を効果的にモニタするには、クラスタの状態をオンタイムで表示してくれる crm_mon をひとつのターミナルで起動しておく。
# crm_mon -f -V
さてここで、PINGD チェックが失敗するように、現在アクティブなノードで、ネットワークケーブルを抜くか、下記のような iptables ルールを投入して ping の着信を妨害してみる。
# iptables -A INPUT -p icmp -s 192.168.1.254 -j DROP
何も調整しない状態では、PINGD が1度失敗しただけで、リソースは別ノードへ移る。そして、iptables ルールを削除して再び ping 応答が受け取れるようにする。
# iptables -F INPUT
そうすると、何も命令しないのにリソースはまた最初のノードへ戻ってくる。この動きでいい場合もあるだろうが、実運用を考えるとあまり宜しくない。サービス提供が2度止まるし、障害条件によってはリソースがノード間を何度もシーソーしてしまう可能性があるからだ。
リソースに失敗が何回起こったらフェイルオーバーするかは、migration-threshold パラメータでコントロールできる。これはリソース毎に設定できるが、幾つものリソースに対して設定するのは手間が掛かるので、リソース全般のデフォルト値を変えてやる。例外にしたいリソースがあれば、個別に migration-threshold を設定すればそのリソースだけデフォルトをオーバーライドできる。失敗 2回までは同じノード上でリソースを再起動し、3回目でフェイルオーバーするようにするには、
# pcs resource rsc defaults migration-threshold=3
失敗回数は cib に、ノード毎かつリソース毎に記録される。既定では自動リセットは行われない。つまり、制約と相まって、そのノードへはもうフェイルオーバーできない。この挙動を司るのが failure-timeout。1時間後にフェイルカウントがリセットされるようにするには、
# pcs resource rsc defaults failure-timeout=60m
元いたノードが健常性を取り戻しても自動フェイルバックしないようにするには、resource-stickiness を変える。
# pcs resource rsc defaults resource-stickiness=INFINITY
設定されたことを pcs で確認するには、
# pcs resource rsc defaults
では、調整結果をテストしてみよう。PINGD は設定や疑似テストの方法によってはフェイルカウントが上がらないので、l7vsd デーモンを停止させる試験に切り替えてみるといいだろう。
# crm_mon -f -V
# service l7vsd stop
リソースが再起動されたのを crm_mon の画面で確認したら、あと2回、同様に l7vsd を stop してみる。フェイルオーバーが起こるはずだ。元いたノード上で L7VSD リソースのフェイルカウントを確認してみよう。
# crm_failcount -r L7VSD [-N centos6u]
crm コマンドでやる場合は、
# crm resource failcount L7VSD show centos6u
L7VSDはL7VSD-clone としてクローンしてあるが、フェイルカウントはクローン元のリソース名と結びついて記録されるようだ。
1時間も待てないので今すぐフェイルカウントをリセットしたいと思うだろう。手動で即座にリセットするには、
# crm_failcount -r L7VSD -v 0 [-N centos6u]
crm コマンドなら、
# crm resource cleanup L7VSD [centos6u]
または、
# crm resource failcount L7VSD set centos6u 0
ちょっとクセがあるので触れておかなくてはならない。リソースを手動でマイグレーション(移動)させるには、pcs なら、
# pcs resource move GrpBalancer [centos6u2]
crm コマンドなら、
# crm resource move GrpBalancer [centos6u2]
で手動移動できる。ただし、移動後の状態にひとつ小難しい点があって、元いたノードに対して「もうこっちでは活性化させない」というlocation制約が立ってしまうのだ。この状態でも手動マイグレーションは可能で、もう一度手動マイグレーションをして居場所を戻せば、この制約は消去され、今度はさっきいたノードのほうにlocation制約が立つ。しかし、このままでは自動フェイルオーバーは阻害されてしまう。立ってしまったこの制約を取り除くには、
# pcs constraint location rm cli-standby-<RSC_NAME> [NODE]
<RSC_NAME> の部分には当該のリソース名が付く。例えば cli-standby-GrpBalancer という具合だ。crm の場合のコマンドは、
# crm configure crm# delete cli-standby-GrpBalancer [centos6u] crm# commit
といった具合だ。
STONITH (Shoot The Other Node In The Head: "他のノードの脳天に一発ぶちかます" - Fencing とも言う) は、ノード間の全てのハートビートデバイスが使用不能(スプリットブレイン)に陥った時に、排他であるべきリソースが同時に活性化するのを防ぐ機構。物理マシンであれば、サーバリモートコントロールボード(DELLのDRAC等)や、UPSのSNMPボードなどを STONITH デバイスにしてノードを緊急シャットダウン/リブートさせることができる。当検証ではノードはKVMの仮想マシンなので、仮想マシンインフラを使った STONITH を実装する。この場合の STONITH デバイスは KVMホストのハイパーバイザということになる。
さて、ここでもまた、CMAN が噛むことによる複雑さが首をもたげる。以下で詳細に設定する STONITH デバイスは Pacemaker の管理下にあるものなのだが、Fencing の必要性を判断してキックするのは CMAN なのだ。そのため、CMAN 側には、STONITH デバイスそのものではなく Pacemaker の持つ STONITH デバイスへのリダイレクタというやつを指定して、間接的にキックさせる構造となる(Clusters from Scratchの"Configuring CMAN Fencing"を参照)。
各ノードに、必要なパッケージをインストールする。
fence_virsh でノードをシャットダウンするには、ノード上で libvirt agent が動いていなければならない(vSphereにおけるVMware Toolsのような存在)。RHEL/CentOS 6 では libvirt-client パッケージがそれにあたる。virsh コマンドもこれに含まれている。インストールと起動の確認をしておこう。
# rpm -q libvirt-client # chkconfig libvirt-guests --list # service libvirt-guests status # which virsh
各種 STONITH エージェントは fence-agents パッケージに含まれる。
# yum install fence-agents
Package Arch Version Repository Size
==============================================================================
Installing:
fence-agents x86_64 3.1.5-25.el6_4.2 updates 161 k
Installing for dependencies:
perl-Net-Telnet noarch 3.03-11.el6 base 56 k
pexpect noarch 2.3-6.el6 base 147 k
python-suds noarch 0.4.1-3.el6 base 218 k
/usr/sbin/ に fence_* というファイル名のエージェントが幾つかインストールされる。言語は phython、perl、sh といろいろだ。VMware環境用のエージェントも見受けられる。
このパッケージの取り揃えでは、stonith:fence_virsh という STONITH エージェントを使う。Linux-HA Japan提供パッケージを使ったソフトウェア構成(次ページで紹介) では stonith:external/libvirt というプラグイン形式のエージェント (cluster-glueパッケージに含まれる) を使うのだが、試してみたところ、RedHatでビルドされたこのバージョンの Pacemaker パッケージとは互換性がないようだ。
fence_virsh は、緊急シャットダウンに virsh を使い、KVMホストの libvirt フレームワークに対して qemu+ssh:// で接続して reboot コマンドなどを投入する。そのため、各ノード上の root ユーザ用に生成したパブリックキーを、KVMホストに登録しておく必要がある。詳しい手順は KVMのページ の KVMのリモート管理-sshトンネルを介した接続 を参照していただきたい。非対称鍵の生成時には、パスフレーズもきちんと入力すること。fence_virshにはパスフレーズを指定するためのパラメータがちゃんとある。
fence_virsh には、qemu+tls:// や パスワード認証付き qemu+tcp:// でハイパーバイザに接続する仕掛けはないようだ。ただし、ホスト側の libvirtd はそれらの接続待ち受け方式を並存させておくことができるので、既存の virt-manager などからの接続環境を根こそぎ見直す必要はない。
これも混乱の元なのだが、当バージョンの Pacemaker では、STONITH の管理ツールは stonith_admin だ。別の Pacemaker パッケージでは代わりに stonith コマンドだったりする。
使用可能な STONITH エージェントがあることを確認する。
# stonith_admin -I
fence_virshエージェントのオプションなどを調べるには、
# crm ra info stonith:fence_virsh
上記の方が出力内容が詳しいが、pcs でも出力は可能。
# pcs stonith describe fence_virsh
ここでひとつ前準備がある。cib にパスワードやパスフレーズを直接書くのはセキュリティ上宜しくない。有難いことに、fence_virsh では passwd_script というパラメータが使えるので、そこに指定するための小スクリプトを作成しておく。パスはどこでもいいのだが、例えば /usr/local/bin/ に .fence_virsh_secret というシェルスクリプトを置く。
#!/bin/sh echo my_pasword
作ったら、パーミッションを root:root 500 に絞り上げる。
さて、定義作成に入る。残念ながら現在の pcs ではリソースの meta 属性が定義できないため、定義作成には crm を使う。ここでは、crm の shadow cib という機能を使って cib のコピーを編集し、最後に本体へマージするやり方を挙げる。まず、シャドウcibを作成して、configureモードに入る。
# crm crm# cib new stonith_cfg crm# configure
プライマリノードを撃ち殺すほうの STONITH。KVMホストの IPが 192.168.1.6 と仮定。 幾つか、規定値であるため本来書かなくてもいいパラメータもあるが、キーポイントとなるものは書いてある。
crm# primitive fence_virsh_primary stonith:fence_virsh \ params ipaddr=192.168.1.6 inet4_only=true \ login=root passwd_script=/usr/local/bin/.fence_virsh_secret \ identity_file=/root/.ssh/id_rsa port=centos6u action=reboot delay=15 \ pcmk_host_list=centos6u pcmk_host_check=static-list pcmk_host_map="" \ op start interval=0s timeout=60s \ op monitor interval=30m timeout=10s \ meta migration-threshold=INFINITY failure-timeout=60s
port はこの STONITH で制御対象とする仮想マシンのハイパーバイザ上における登録名。pcmk_host_list も同じ。 delay を 15秒つけているのは、スレーブノード用 STONITH との相撃ちによるノード全滅を避けるためだ。meta 属性は、前に設定したリソースのグローバルデフォルトをオーバーライドするためのもの。STONITH リソースは他のリソースとの依存関係がほとんどなく、可能な限り動き続けてほしいからだ。モニター間隔は、フェンシング自体のトリガータイミングではなく STONITH デバイス自体の機能性確認間隔のようなので、30分以上で充分 (SUSE のドキュメント)。
スレーブノード用もほぼ同様に定義。ただし、delay はとらない。
crm# primitive fence_virsh_slave stonith:fence_virsh \ params ipaddr=192.168.1.6 inet4_only=true \ login=root passwd_script=/usr/local/bin/.fence_virsh_secret \ identity_file=/root/.ssh/id_rsa port=centos6u2 action=reboot \ pcmk_host_list=centos6u2 pcmk_host_check=static-list pcmk_host_map="" \ op start interval=0s timeout=60s \ op monitor interval=30m timeout=10s \ meta migration-threshold=INFINITY failure-timeout=60s
STONITH は自分で自ノードをシャットダウンすることはできない。ノードのネットワークインターフェイスがひとつ残らず機能停止した場合を考えれば分かるだろう。よって、マスターノードを殺す STONITH リソースはマスターノード自身以外の上で、スレーブノードを殺すほうはスレーブノード以外で活性化するような位置制約を定義する。
crm# location loc-fence_virsh_primary fence_virsh_primary -inf: centos6u crm# location loc-fence_virsh_slave fence_virsh_slave -inf: centos6u2
定義が揃ったので、クラスタのグローバルパラメータ stonith-enabled を有効にする設定も盛り込み、本体 cib に反映する。
crm# property stonith-enabled=true crm# commit crm# cd crm# cib commit stonith_cfg crm# quit # crm cib delete stonith_cfg # stonith_admin -L # crm status
/etc/cluster/cluster.conf を編集してもよいが、ここでは ccs ツールを使うことにする。
まず、Fencing 挙動のグローバルパラメータを調整する。post_fail_delay は、CMAN がスプリットブレインを感知してからノードをフェンシングするまでの待機秒数、post_join_delay はフェンシングドメインに参加してからの待ち秒数。この両方のパラメータを設定する場合、コマンドを 2回に分けては駄目。
# ccs -h centos6u --setfencedaemon post_fail_delay=20 post_join_delay=30
Pacemaker の Fencing デバイスへのリダイレクタを登録する。fence_pcmk というのがそのリダイレクタ。-h の引数は、どのノード上にある cluster.conf に対する設定命令かを示す。
# ccs -h centos6u --addfencedev pcmk agent=fence_pcmk name=pcmk
ノード定義毎に、上の name を使ってフェンシングデバイスを付与する。
# ccs -h centos6u --addmethod pcmk-redirect centos6u # ccs -h centos6u --addfenceinst pcmk centos6u pcmk-redirect \ port=centos6u action=off # ccs -h centos6u --addmethod pcmk-redirect centos6u2 # ccs -h centos6u --addfenceinst pcmk centos6u2 pcmk-redirect \ port=centos6u2 action=off
設定変更を他のノードの cluster.conf へも同期。
# ccs -h centos6u --sync --activate # ccs -h centos6u --checkconf
上記コマンドの結果は cluster.conf にこういった感じで刻み込まれる。
<?xml version="1.0"?>
<cluster config_version="12" name="monkeyclst1">
<logging debug="off" syslog_facility="local5" syslog_priority="info" to_logfile="no" to_syslog="yes"/>
<cman expected_votes="1" two_node="1"/>
<clusternodes>
<clusternode name="centos6u" nodeid="24">
<altname name="192.168.255.24"/>
<fence>
<method name="pcmk-redirect">
<device action="off" name="pcmk" port="centos6u"/>
</method>
</fence>
</clusternode>
<clusternode name="centos6u2" nodeid="25">
<altname name="192.168.255.25"/>
<fence>
<method name="pcmk-redirect">
<device action="off" name="pcmk" port="centos6u2"/>
</method>
</fence>
</clusternode>
</clusternodes>
<fence_daemon post_fail_delay="20" post_join_delay="30"/>
<fencedevices>
<fencedevice agent="fence_pcmk" name="pcmk"/>
</fencedevices>
<rm>
<failoverdomains/>
<resources/>
</rm>
</cluster>
Pacemaker 側の fence_virsh は action として reboot しか設定できず、action=shutdown という設定はエラーとなり受け入れられない。しかし、fence_virsh 側がその状態でも、CMAN側でのフェンシングデバイス定義で action=off にしておくと、フェンシングされたノードはリブートでなく落ちたままになる。CMAN側も reboot にした場合はノードはリブートされてまたすぐにクラスタメンバに復帰する。CMAN側では action=disable という設定もありのはずだが、期待した「リブートされるがクラスタメンバとしては無効状態になる」という動きにはならず、見た目上 reboot と同じ動作となった。 本当にNIC全部に継続的な障害が起きていた場合、リブートが際限なく繰り返される可能性が高いので、上記の設定が今のところ最良ではないかと思う。
手動によるフェンシング発動。
# stonith_admin --reboot centos6u2
自律的なフェンシングテスト。現在 GrpBalancer リソースの活性化しているほうのノードでクラスタモニタを立ち上げておく。
# crm_mon -V
そして、もう一方のノードで、TCP, UDP, ICMP全てをブロックすることによりネットワークインターフェイス全障害をエミュレートする。
# iptables -A INPUT -p all -j DROP
post_fail_delay 時間+α経過後、後者のノードがリブートされるはずだ。